What is Overfitting in ML/DL and how can we overcome this.
Out of all things that can go wrong with your ML model, overfitting might be the most common one. If your model is not generalizing well on unseen data then you know you have an overfitting problem.
- By Lakshay Wadhwa, CoffeeBeans Consulting.

Overfitting is a phenomenon that generally happens when a model models the training data too well and the model also picks up the noise and fluctuations in the training data. The problem then occurs on the new data where the model fails to generalize and hence the model does not give the desired output.

The green line represents the overfit model and the black line represents a regularized model.
Why does Overfitting happens?
Overfitting occurs when our ML/DL model tries to cover almost all data points in the training set during training phase. This led to model learning the noise in the data as well. The overfitted model generally has low bias and high variance.
What is Bias and what is variance?
Bias is defined as the difference between the average predicted value and the actual value. It also describes how well the model matches the training data set. A low bias model matches the training dataset well whereas the high bias model would not match the training dataset well.
How do we know a model has high bias?
- It fails to capture the trends in the data.
- High error rate.
- Possible underfitting on the dataset.
Variance measures how far a data set is dispersed. Mathematically, it is simply defined as the average of the squared differences of the data points from the mean value.
How we know a model has high variance?
- It usually has noise in the data.
- More complex models.
- Possible overfitting on the dataset.
How bias and variance are connected?
Bias and variance are inversely connected and it’s next to impossible to get a model with low bias and low variance because of the relation between them.
Generally a model too simple with less number of parameters has a high bias generally whereas a model with greater number of parameters has a high variance. We should aim for a right balance between these two to train a model that is not so underfit and not so overfit.

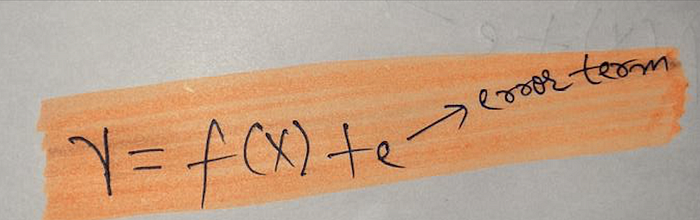
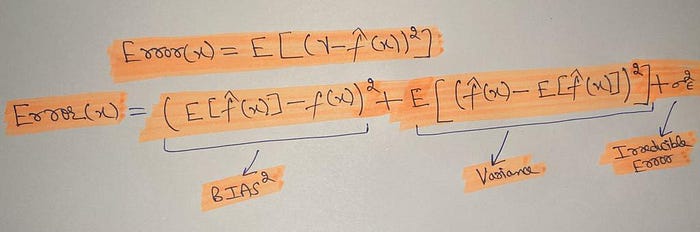
How to overcome overfitting?
- Cross-validation:
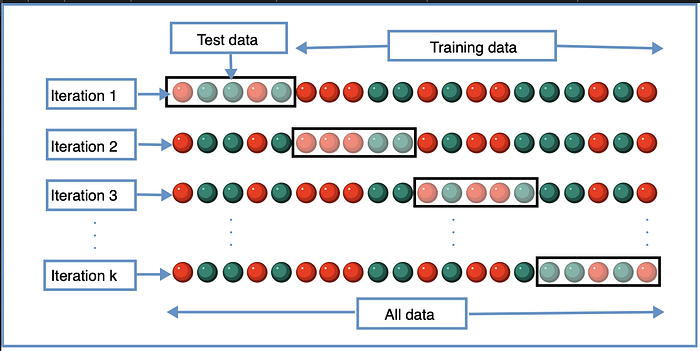
The idea is very simple, we take the training data and split this into multiple training/testing data sets. Using k-fold cross-validation, we partition the data into k subsets known as folds. We then train iteratively on k-1 folds and gets the result on the remaining fold in each iteration. So in each iteration, the model trains on k-1 folds and then we get the accuracy on the remaining fold. For all iterations, we average the results at the end to get the final accuracy.
2. Regularization techniques:
Regularization is a technique that is used to reduce overfitting by fitting the function appropriately on the given training set. Regularization techniques have different forms depending on the type of problem we are solving. In decision trees, we can use pruning, in regression we can add a penalty term, basically, we can use L1 and L2 regularization techniques. In neural networks, we can use dropout layers, etc.
a) Early stopping:
While iteratively training the model, we could check how the model is performing in each iteration. Generally, a model performance improves until a certain number of iterations, after that point it overfits the data and hence the performance starts to deprecate. Early stopping basically means to stop the training before the model starts to overfit the data.
b) Data Augmentation:
Training with more data might help the algorithm learn more hidden patterns in the data. It might not work every time, for example, if there is too much noise in the data, this might not work. Hence, cleaning the data is very much required every time before the training stage.
c) Dropouts:
This is another frequently used regularization technique in which we randomly turned off some neurons during the training process. It means these neurons will not be able to affect the activation in the forward pass and the updation of the weights during the backward pass.
d) L1 and L2 regularization:
A regression model that uses the L1 technique is known as Lasso regression and if it uses L2 technique it is known as Ridge regression.
The main difference between them is the penalty term.
- Lasso Regression:
Lasso Regression adds absolute value of magnitude of coefficient as penalty term to the loss function.
If lambda is zero then we get back to OLS and if lambda is very large value it will make coefficients zero hence it will under-fit.
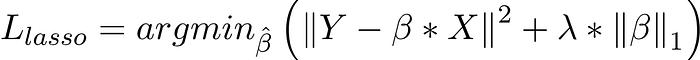
2. Ridge Regression:
Ridge regression adds a squared magnitude of coefficient as penalty term to the loss function.
If lambda is zero then we get back OLS and if lambda is very large then it will add too much weight and it will lead to under-fitting. So we have to choose lambda wisely to avoid overfitting.
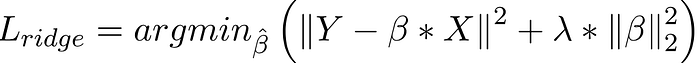
3. Ensemble techniques:
Ensemble are quite common machine learning techniques where we combine the results from various models instead of using only one model. The most common of those are bagging and boosting.
Bagging:
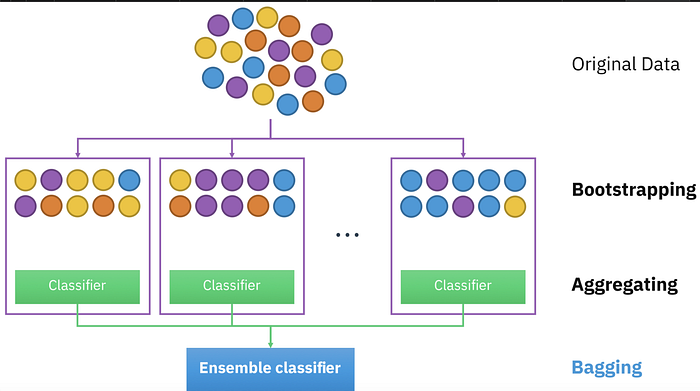
It is also known as bootstrapping aggregation which helps in decreasing the variance and hence, overfitting.
a) It trains a large number of models in parallel.
b) It then smooths out the prediction by averaging out the results.
Boosting:
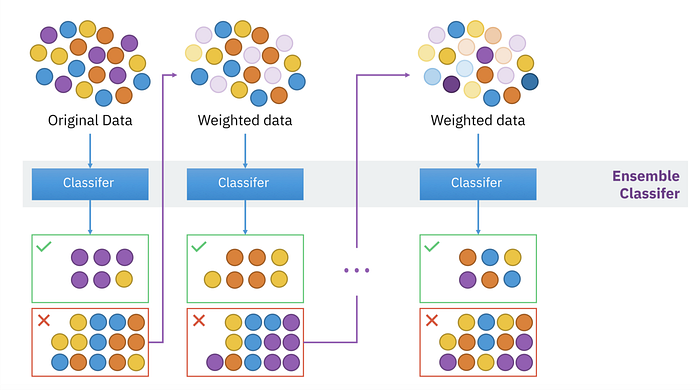
The model starts with a weak learner and gradually we train it in sequence where the next sequential model attempts to correct the error made in the previous model. Basically, we create a lot of strong learner from a number of weak learners trained in sequence.
4. Feature selection:
Overfitting can be reduced by removing unnecessary features, some algorithms have inbuilt feature selection capability and for those who doesn’t have, we can do it manually. Techniques like L1 regularization and random forest feature importance can be used here.
I hope you enjoyed reading this. If any mistake found, please feel free to mention and the blog will be corrected.
